Creating 3D semantic reconstructions of environments is fundamental to many applications, especially when related to autonomous agent operation (e.g. goal-oriented navigation or object interaction and manipulation).
Commonly, 3D semantic reconstruction systems capture the entire scene in the same level of detail.
However, certain tasks (e.g. object interaction) require a fine-grained and high-resolution map, particularly if the objects to interact are of small size or intricate geometry.
In recent practice, this leads to the entire map being in the same high-quality resolution, which results in increased computational and storage costs.
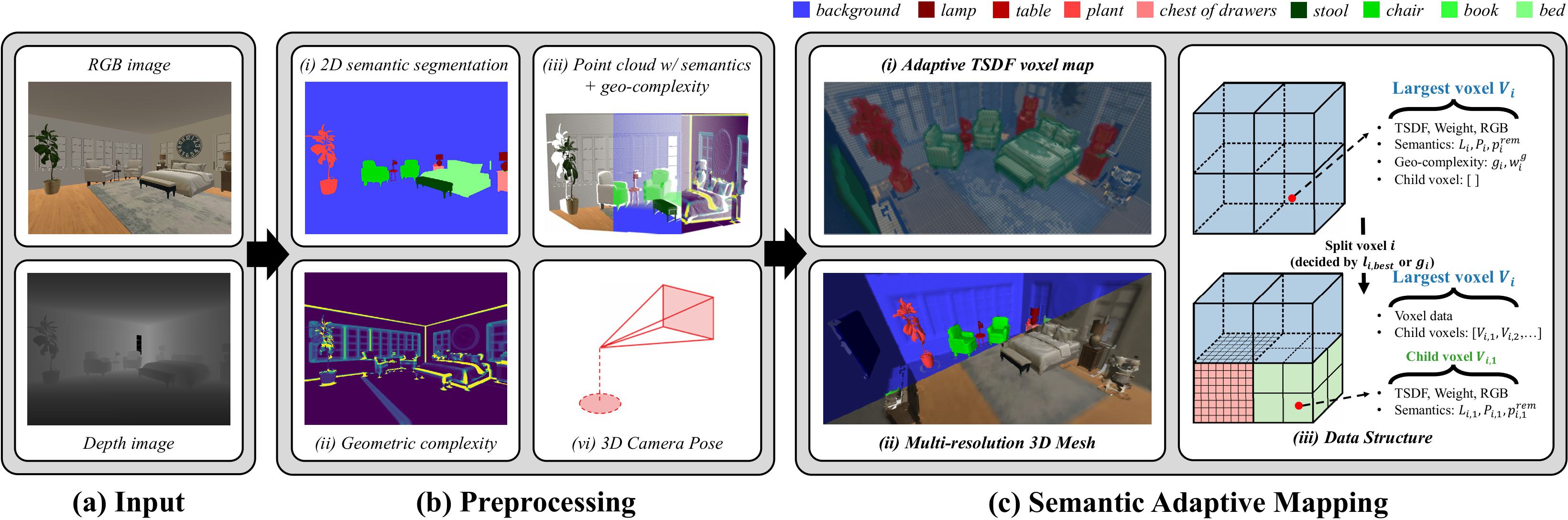
To address this challenge, we propose MAP-ADAPT, a real-time method for quality-adaptive semantic 3D reconstruction using RGBD frames.
MAP-ADAPT is the first adaptive semantic 3D mapping algorithm that, unlike prior work, generates directly a single map with regions of different quality based on both the semantic information and the geometric complexity of the scene.
Leveraging a semantic SLAM pipeline for pose and semantic estimation, we achieve comparable or superior results to state-of-the-art methods on synthetic and real-world data, while significantly reducing storage and computation requirements.
![Fix-size (1cm) [819 MB]](resources/reconstruction/HSSD/fix_1cm.png)
![MAP-ADAPT-S (Ours) [297 MB]](resources/reconstruction/HSSD/ours.png)



![Fix-size (1cm) [463 MB]](resources/reconstruction/ScanNet/fix_1cm.png)
![MAP-ADAPT-S (Ours) [132 MB]](resources/reconstruction/ScanNet/ours.png)



